

In this post, I will describe the general process of creating AI song covers and what is essential at each stage. Before getting into the specifics, it's worth noting that the most representative programs for creating AI song covers until recently (March 2024) are rvc and svc. rvc can be considered a voice modulation system made with vits, while svc is based on a waveform generation method using stable diffusion. Although svc is generally known to produce better quality results, there is no significant difference in quality when used by individuals or the general public. Regarding accessibility and convenience, rvc is overwhelmingly better, so I also used rvc for my production. When using rvc, some people code in their local environment, while others use Colab. Since I am in a Mac environment, I used Colab because AI song covers rely heavily on GPU quality due to their use of machine learning. Even when using TensorFlow on a Mac, the GPU quality is deficient. Therefore, I paid for Colab and produced the covers using the GPU environment provided by Colab. (link) The statistical interpretation learned in machine learning closely relates to good results at each stage. I will briefly mention this at each step.
#1 Data Cleaning
In data science, machine learning, or statistical processes, the first thing we should always do is refine the dataset. The same applies to AI song covers. It's no exaggeration to say that this is one of the two most important tasks in the entire project. The higher the quality of the audio files, the better the results will naturally be. The dataset's source can be voice files recorded by yourself or people around you or audio or voice files of desired singers or streamers. Regardless of what you choose, it's essential to use a high-quality dataset. The more data, the better, but there is no dramatic change beyond a certain point. When using the rvc Colab, 10-15 minutes of dataset is sufficient. Ideally, you should have about 10 minutes of song files and 5 minutes of essay or plain text reading data.
In the realm of machine learning, it's crucial to train the model effectively. Our aim is to precisely refine only the voice we want to learn and infer. To achieve this, it's vital to eliminate noise and the MR (minus one) from the song, leaving only the voice in the audio files. For this process, we need to rely on programs, and the most notable ones are Gaudio Studio (link) and Ultimate Vocal Remover (UVR) (link). Gaudio Studio can be used directly on the web, but our ability to manually manipulate it is limited. Ultimate Vocal Remover may be a bit intricate, but it offers us the power to fine-tune it to our liking. Given that the dataset refinement process is the most crucial, I personally advocate for using UVR. There is also a website (link: ) that specializes in audio separation, where you can discover the optimal combination of models that suits your needs.
To summarize, we need to prepare about 15 minutes of unrefined dataset and then refine it into a dataset for training using the programs mentioned above. This process takes the longest time in the preparation stage and directly affects the results, so I hope you can endure this tedious process well.
#2 Song Audio File Refinement
The next step is to refine the song audio files you want to cover. In the previous process, you prepared the voice to train, and now you need the song audio to infer that voice. As with the voice files, the closer the song files are to the original sound, the better the results will be. After downloading the song files, you need to separate the audio using Gaudio Studio or UVR, just like in the previous process. Since the trained voice is in a state where only the pure voice exists, the song audio requires only the pure voice. Therefore, in this process, you should separate the MR and vocals and remove echo and noise from the separated vocals.
#3 Voice Learning Process
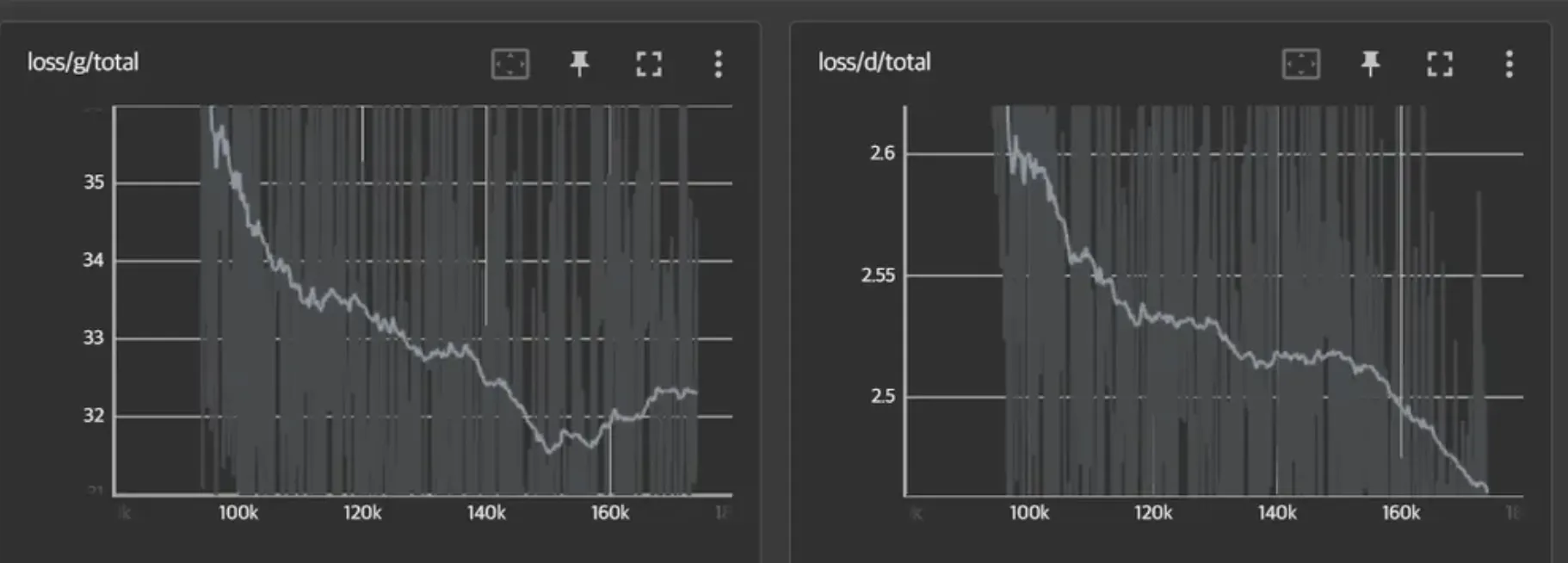
This is the process of training voice data using the rvc Colab. The advantage of the rvc Colab is that it has a well-designed interface, so even first-time users can easily use it. The steps that require selecting or adjusting values are choosing the pitch extraction algorithm and setting the size of epochs and batches. The results may vary depending on the model for pitch extraction, but selecting the rvmpe or mangio crepe model should be fine. Generally, larger values for epochs and batches may likely yield better results, but a point to be cautious about in the statistical learning process is overfitting. The rvc Colab displays the values to avoid overfitting in a TensorBoard graph, making it easy to identify. The example image below shows that overfitting occurs around the 150k step, leading to a decrease in learning effectiveness. Therefore, we can determine the number of training iterations. This process also demonstrates the importance of statistical knowledge and interpretation.
#4 Voice Inference Process
This process is even more straightforward than training, so don't worry. You need the trained voice from the previous process and the vocal file separated from the song audio file earlier. During the inference process, you must also select a pitch extraction algorithm, and rvmpe is generally a good choice. In this process, you can change the octave to infer voices of different genders, and if the vocal characteristics of the song audio file are too strong, you can slightly mitigate them during inference. However, even with mitigation, there's a limit, so if you infer a voice on a song with firm vocal characteristics, you're unlikely to get good results. Therefore, using a song with a very neutral and moderate vocal style is more likely to yield good results.
#5 Audio Mixing Process
The final step we need to take is to mix the inferred voice back with the MR (minus one) to complete the song. In the #2 process, we separated the vocals and MR from the song file, and we can now use that MR again. Do you remember when I mentioned that one of the two most important processes while describing #1? The remaining most crucial process is the mixing process. Even if you have created a reasonable inference result with good data, listeners will inevitably find it uncomfortable if the final mixing feels awkward. While working on this project, I realized how significant statistics and machine learning are, but at the same time, I realized that statistics and machine learning cannot be the result itself. There are Cubase for Windows and Logic Pro for Mac for mixing programs. Adobe Audition is available for both platforms, and I used Adobe Audition for mixing. The critical points in mixing are the volume balance between the voice and MR, and since the inferred voice is in a pure state without any echo or other effects, you need to add spatialization or echo to make it blend well with the MR. If the original song had a lot of chorus, it would be more natural to infer and mix the chorus.
Concluding Remarks
While explaining the process in writing may seem lengthy and complicated, if you try it once and have statistical knowledge, you can create an AI song cover more quickly than you might think. As mentioned in the previous process, as a statistics student, I believed that statistical processes or interpretations often became the results. I usually focused on that during my studies. However, through this AI song cover process, I realized that while statistical knowledge and interpretation are essential and critical for making every step easier and producing better results, they are ultimately not the end product. This realization is even more crucial as I proceed with future work. It was an excellent opportunity to understand where statistics is used and what we should focus on in every task and collaborative process.